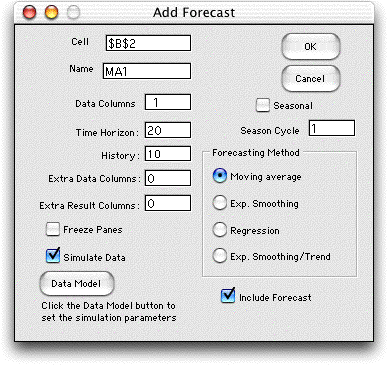
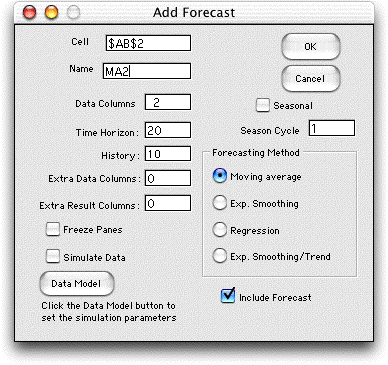
| The Data Columns field
specifies the number of individual time series that will be
placed on the display. It might be useful to have more than
one if the user has a several series to be simultaneously tracked
such as the stock prices in a portfolio or the sales volumes
for different products. Each time series will have a separate
forecast.
The Time Horizon is the number of periods
to be included in the series. This number can be changed using
the Change command. The History is the number
of periods of data used to obtain the first forecast. All the
methods require this warm-up period to obtain valid
forecasts. This history is important because it limits several
features of the forecast. For instance the number of observations
in a moving average and the number of observations in a regression
forecast are limited to the number of periods in the history.
The forecast interval is also limited by the history.
A nonzero entry in the Extra Data Columns field will
cause the add-in to create extra columns that are placed to
the left of the data columns. These might be useful for holding
associated information related to the data. For example on the
Investments page we use a
single extra data column to hold the dates associated with closing
stock prices.
A nonzero entry in the Extra Results Columns field
will cause the add-in to create extra columns in the display
that appear to the right of the forecasts. These might be useful
for additional processing of the forecasts. This is illustrated
on the Investments page where
we use several extra columns to make stock buy and sell decisions.
When the Simulate button is checked, data will be
simulated using Monte Carlo simulation. The results are similar
to the Simulation command on the forecast menu, but
the data placed on the worksheet is fixed, rather than controllable
through simulation parameters.
When the Freeze Panes button is checked, the worksheet
window is divided into four sections and the panes are frozen.
This is useful for large data sets where the active data cells
may be far removed from the row and column titles.
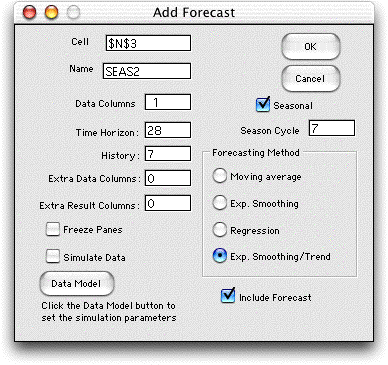
The Seasonal button allows the analysis of time series
with cyclical variations. The number of data points in a cycle
is placed in the field below the button.
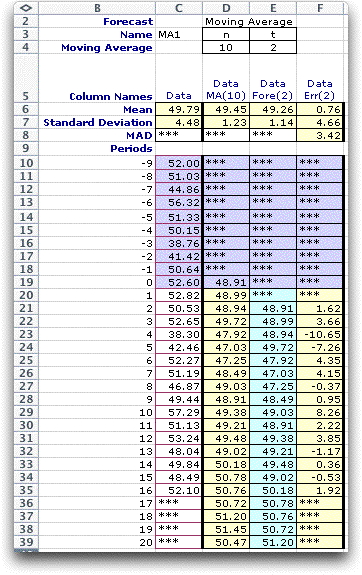
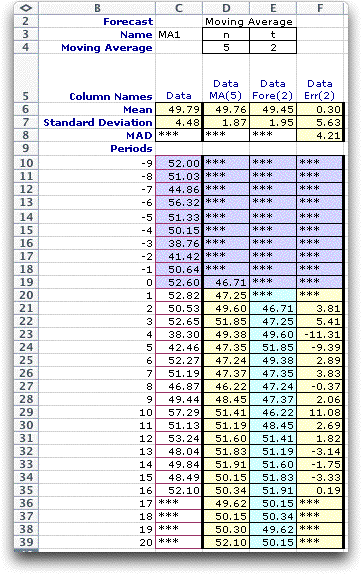
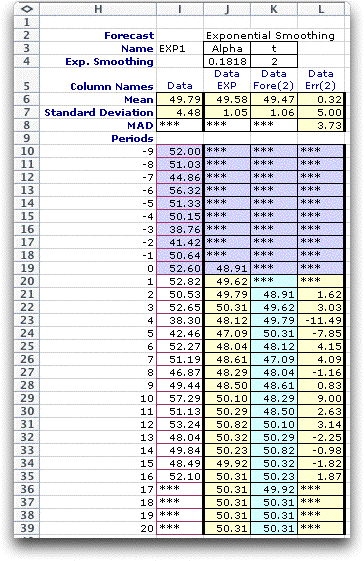
The Include Forecast button determines whether the
display will include forecasts for future times. For example
a moving average forecast places one column on the display holding
the moving average. When this button is checked, two additional
columns are also included, one holding forecasts for future
times and one holding error measurements for the forecast. Usually
one would check this button, but for some applications future
forecasts are not required. Again we illustrate this on the
Investments page. The other
pages of this section all include forecasts.
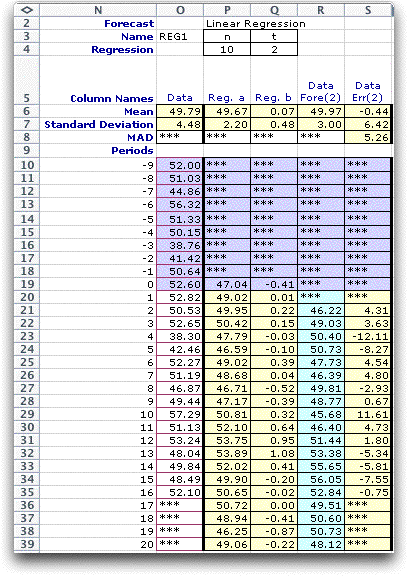
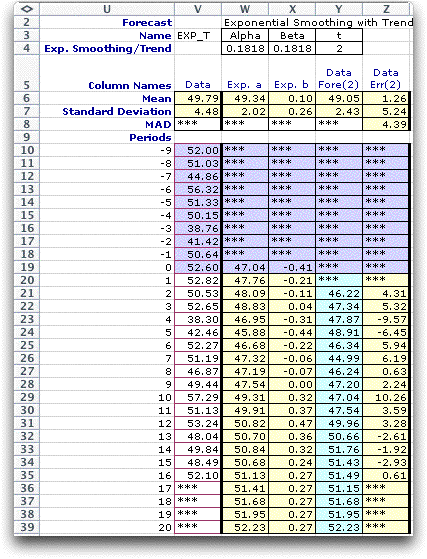
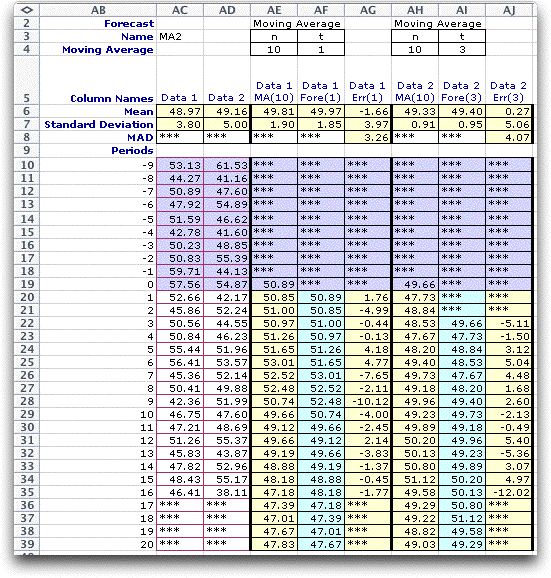
The dialog requires the selection of one of the forecasting
methods using the buttons on the right. In the remainder of
this page, we illustrate the various forecasting methods. |