|
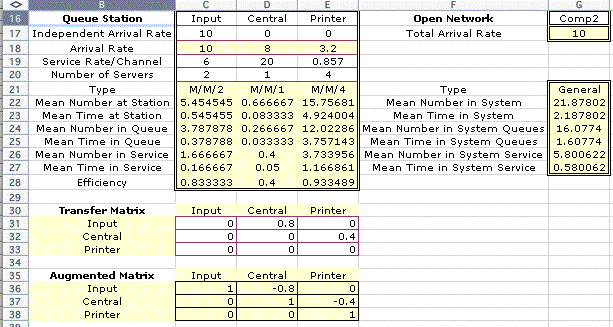
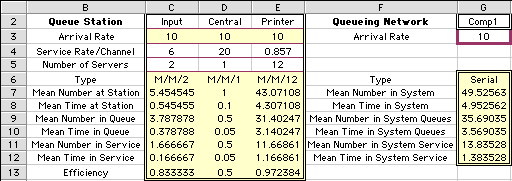
The remainder of the rows of the display show the results
that are computed with the queueing functions provided by
the add-in. The rows in columns C, D, and E describe the results
for the individual stations. The station results are added
together to obtain the system results in column G. For a network
with arrivals and services governed by exponential distributions,
each queueing station may be analyzed independently with the
formulas derived for Poisson processes.
Reviewing the efficiencies for the three stations reveals
that the central process is the least busy, while the printers
are busy 97% of the time. Of the almost 50 jobs in the system,
on the average, 43 of them are waiting or in process at the
printers. From the system results we see that on the average
a job spends about 5 minutes in the system.
Any number not colored yellow may be changed by the user
to obtain new results. For example, one might wonder if increasing
the number of printers would result in significantly lower
throughput times for jobs. That can be immediately determined
by increasing the number in cell E5.
The General Network
To illustrate the general network, we modify the problem
slightly by changing the proportions of the jobs passing through
each device.
All jobs must go through the input processor. Because of
errors, only 80% of the jobs go through the central processor.
Only 40% of the jobs passing through the central processor
go to the output printer.
Since the different numbers of jobs pass through each device,
we must use the General network option. The display
for this option is shown below with the data entered for the
computer problem. The display has been placed with its upper-left
corner at cell B16.
For this option, a new data item appears in row 17, the Independent
Arrival Rate. Each station may have arrivals from outside
the system as indicated by the entries in this row. For the
current example, all arrivals occur to the Input processor,
so the other entries in this row are 0. The arrival rate in
row 18 is a computed quantity and the contents of the row
should not be changed. As before, the service rates and number
of servers are controlled by the user. The numbers of servers
shown here are the smallest numbers that will satisfy the
demand at the three stations.
Data concerning the proportions of jobs passing from one
station to another is entered in the table in the range C31:E33.
We call this the transfer matrix because it shows the proportions
of the flow transferred from one station to another. In row
31 we see that 80% of the flow transfers from the Input processor
to the Central processor. The remaining 20% leaves the network.
From row 32 we see that 40% of the flow passing through the
Central processor goes to the printer.
The arrival rate shown in row 18 is computed with an equation
involving the Inverse of the Augmented matrix. The
Augmented matrix is the transfer matrix subtracted
from the identity matrix The entries in the Transfer matrix
are entirely general as long as the Inverse exists. An entry
on the diagonal represents a recycling through the station.
In many cases the numbers in the matrix represent proportions
of flow transferred. A requirement of the Jackson network
is that the routing be probabilistic. That is, a particular
entity leaving a station will transfer the next with the given
probability distribution.
|